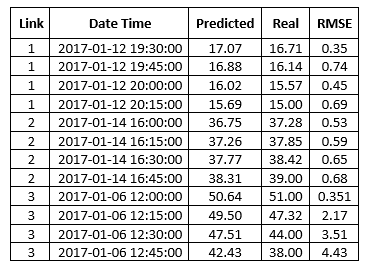
HIT partipiacted in TRANFOR19, a transportation forecasting competition organized by ABJ70 Artificial Intelligence and Advanced Computing Applications and supported by IEEE ITSS Technical Activities Sub-Committee “Smart Cities and Smart Mobility”
The scope of the competition is to evaluate the accuracy of statistical, or CI methods in transportation data forecasting with particular reference to short term traffic forecasting. The focus will be on obtaining predictions, as close as possible to the real data. Solutions that will advance the current understanding in advanced computing, data preprocessing and traffic dynamics will be also favored. The competition is open to Teams (single participant or group of participants) that are willing to present their work at the 2019 TRB Annual Meeting.
Available data (Database definition)
The available data sets include data for October and November of 2016 (61 text files in total). Each file contains information about the vehicle’s exact position on the road segment, the precise generation timestamp of the GPS entry, the driver and the order IDs. All IDs were encrypted and anonymized. Due to the large size and complexity of the input data sets, the first step on the data preparation stage was to import the text files into an RDBMS in order to perform basic data filtering and data transformations and to enable further processing. The RDBMS of our choice was the Microsoft SQL Server 2016 database software. During the data import phase, we performed the following actions on the complete data set:
• Creation of UTC+8 timestamp (local time in China) from the supplied epoch timestamp.
• Conversion of the GPS coordinates from the GCJ-02 to the WGS-84 projection system.
• Calculation of the distance travelled between subsequent GPS entries of the same driver and order (in meters).
• Estimation of the moving speeds (in km/hour) and orientations (in degrees from North).
• Whether a GPS entry was recorded inside the road section of interest (North or South) or not.
The import process took several hours to complete. The resulting table contained 1,560,295,942 rows and included the complete data from all 61 input files.
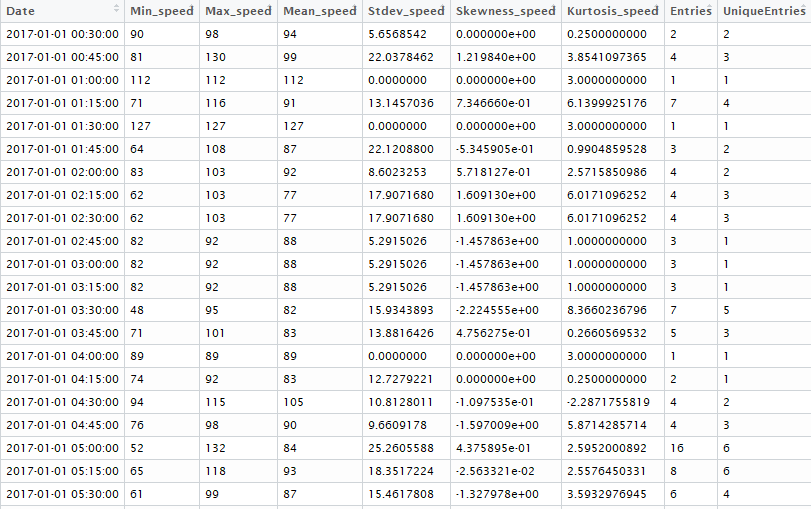
We continued the data preparation process by creating the appropriate database indexes in order to speed up the execution time of the queries we were to perform next. Then we calculated the following metrics in a five minutes time window: The minimum, maximum, average, median, interquartile mean, standard deviation, variation, skewness, kurtosis values of the observed moving speeds of the vehicles, as well as the total number of GPS entries, the number of unique trips and the number of unique vehicles that produced the GPS entries.
Connecting Python to SQL server and preprocessing
The next steps of analysis where completed in Python. Two main datasets were selected from the database. The first contains all historical GPS pulses on the targeted road section and the second contains pulses on 13 surrounding roads, which were defined as polygons in QGIS software and imported into Python for filtering. The python scripts for connecting to the SQL database and fetching requested data are ‘surrounding road data.py’ and ‘target road data.py’. The purpose of extracting data from surrounding roads was to examine correlation between average speeds of those roads and the targeted one. Since the volume of data was huge, surrounding road data were selected for only 8 days, from 14 to 18 and from 28 to 30 of November. Those days were picked because they are weekdays and according to historical weather sites the weather conditions those days were similar with the target day (1st December). The data from the above database queries were saved in pickle format:
a) target_road_north.pkl (target road north direction data)
b) target_road_south.pkl (target road south direction data)
c) dataset_ 28to30.pkl (surrounding roads pulse data, 28 to 30 November)
d) dataset_14to18.pkl (surrounding roads pulse data, 14 to 18 November)
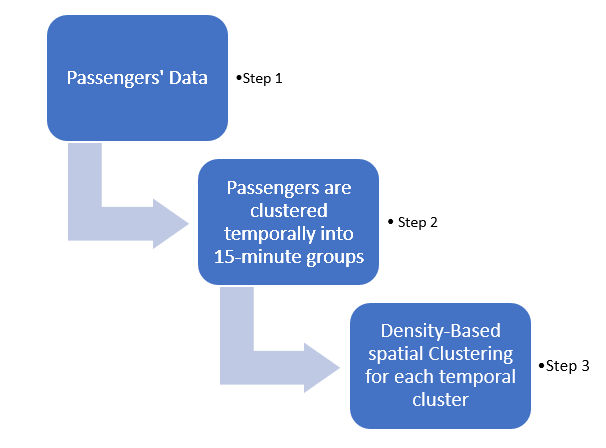
As a next step, data from surrounding roads (c and d) were used as input by the module ‘group.py’, which groups GPS records in 5-minute time intervals, extracting distribution statistics. The outputs are saved as pickle files ‘aggregated_dataset_14to18.pkl’ and ‘aggregated_dataset_28to30.pkl’.
Data exploration and visualizations
Two modules were developed for exploring the datasets. In the first script, ‘data exploration.py’, all datasets are imported, certain transformations are applied to the data and several plots and statistic results are produced. Outputs include time series plots, additive decomposition plots, average speed density plots, lag plots, autocorrelation plots, correlation matrix. The second script, ‘cross-corelation.py’, examines the existence of cross correlation between the targeted road average speed and surrounding roads speed at same interval and up to 3 lags in the past.
Outputs from both modules suggest that the time series to be predicted has a strong seasonal component, and there is no strong correlation between the target road and the surrounding ones.
Predictive models
Three predictive models were developed for the purpose of this competition. All machine learning models were evaluated on test sets that were excluded from the training phase, and the hyper-parameter values for each model were optimized using the grid search cross validation method. The described procedures are explained in the models’ scripts in further detail. The python scripts for creating the predictive models are in the ‘scripts’ subfolder of our team’s submission file.
Seasonal Indices
The first is a time series forecasting model that utilizes seasonal indices. This statistical method was implemented because it provides with accurate predictions on seasonal time series without trend, characteristics that were identified in the target time series. The whole procedure is explained and completed in python scripts ‘seas_ind_north.py’ and ‘seas_ind_south.py’, for north and south directions respectively. Each script outputs an excel file with predictions for a whole day, and values for the missing
time periods were manually added in our team’s final predictions file. The scripts also produce visualization of results.
This model’s strength is that it is highly accurate, easy to interpret, computationally inexpensive and therefore fast to implement. On the other hand, this method only works for seasonal time series without trend, so it would not be possible to use this method for predicting speed at other roads that do not have these characteristics.
Long-Short Term Memory (LSTM) Recurrent Neural Network (RNN)
The second model utilizes a state-of-the-art artificial neural network, a RNN with one hidden LSTM layer, specifically designed for time-series prediction. The model is trained with data from a 10-hour time window for one direction, with the first 5 hours used as model input and the other 5 hours as model output (target variable). Four python modules were developed, one for each direction and prediction time interval. Each module outputs two files, the first being the model saved in a format ready to be imported again to python for further analysis, and the second an excel file with the predictions for the corresponding 5-hour interval. The predictions are then manually added to the final prediction csv files.
LSTM models are known for their ability to learn long-term dependencies ‘hidden’ in time series. One disadvantage of utilizing LSTM in this competition is the relatively short duration of available timeseries data.
Dense Neural Network
The third and final model approaches the problem with the same fashion as the LSTM model, utilizing consecutive 10-hour intervals for training, with 5-hour data as input and 5-hour data as target. Again, although the neural network has the capability of modeling complex relations amongst input and output data, the limited timespan of the timeseries is possible to limit the model’s ability for accurate predictions.
Four dense neural network modules were also created for all direction and time-interval period combinations, and each of them outputs the neural network model and a file with the predicted average speeds, which are then manually added to the final prediction csv files.
Both the dense and the LSTM neural networks have a significant advantage in the sense that they can be generalized and expanded to include more input features (variables) in order to enhance predictive accuracy. This is a powerful feature that would empower a real-world application for real-time traffic prediction. Our team developed a dense neural network utilizing data from surrounding roads, but the model’s predictive performance was poor, as predictions were conducted in a stepwise manner using recorded data from surrounding roads but also the predicted speed for the target road at previous steps.







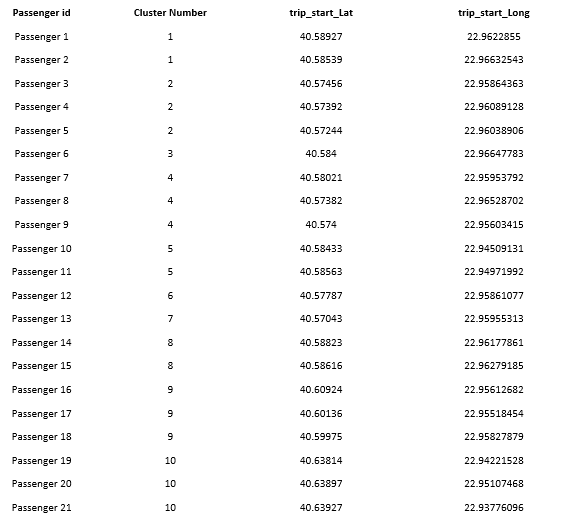
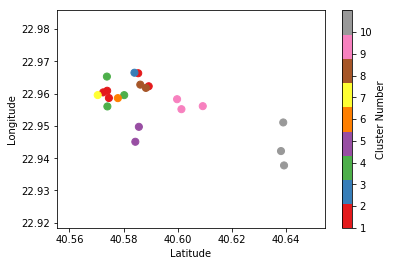
 The input data of the model
The input data of the model
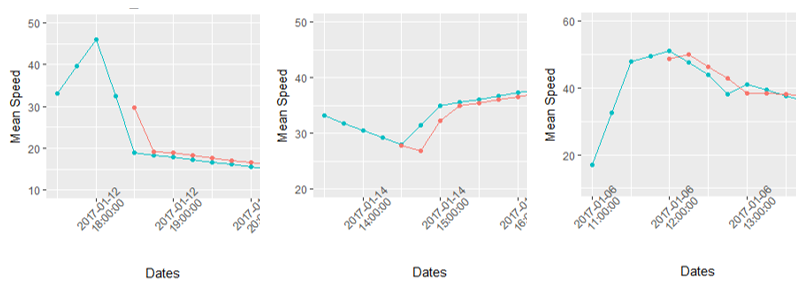 Plot with the Real (blue) and the Predicted (red) values
Plot with the Real (blue) and the Predicted (red) values